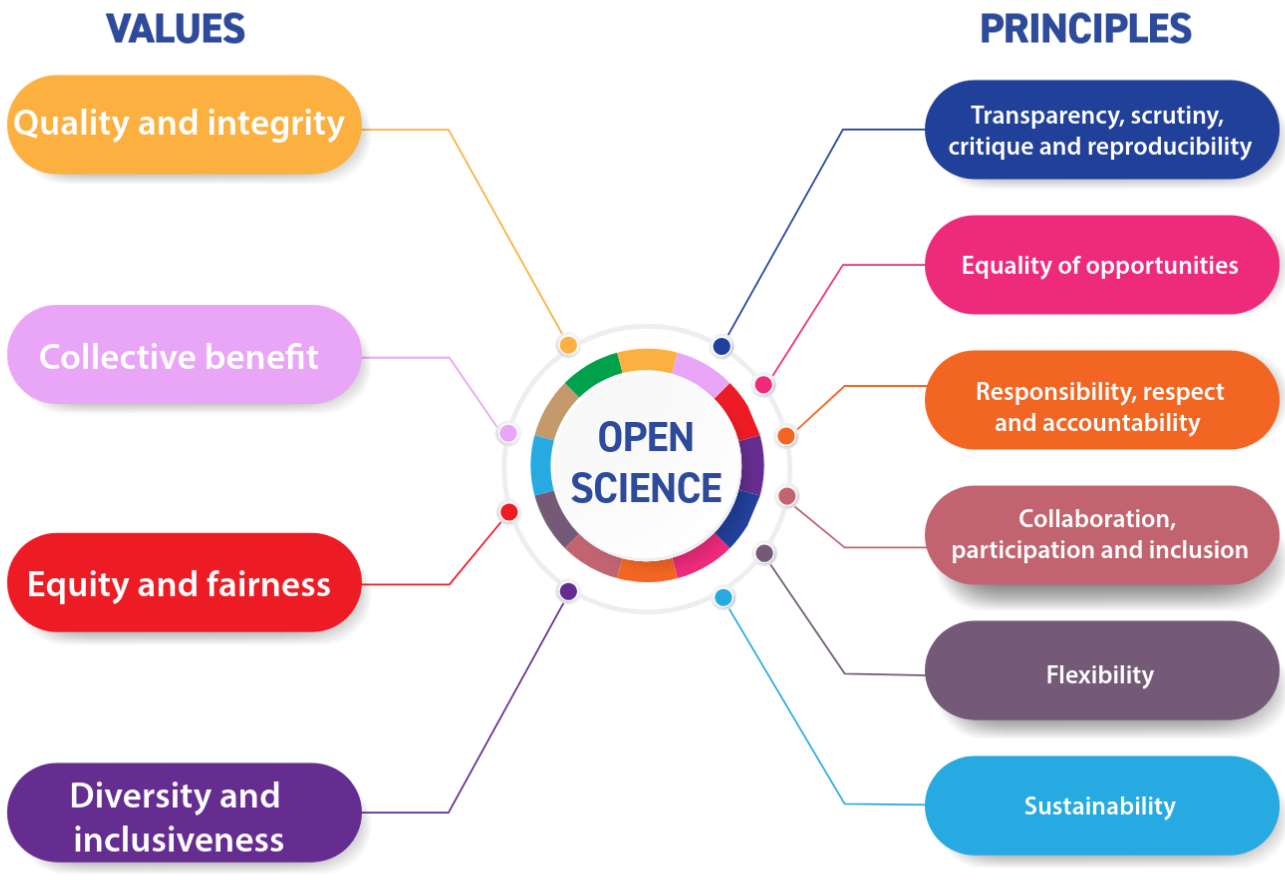
Open Science in (In)Action: Why, What, and How

UNESCO Recommendation on Open Science
The Budapest Open Access Initiative
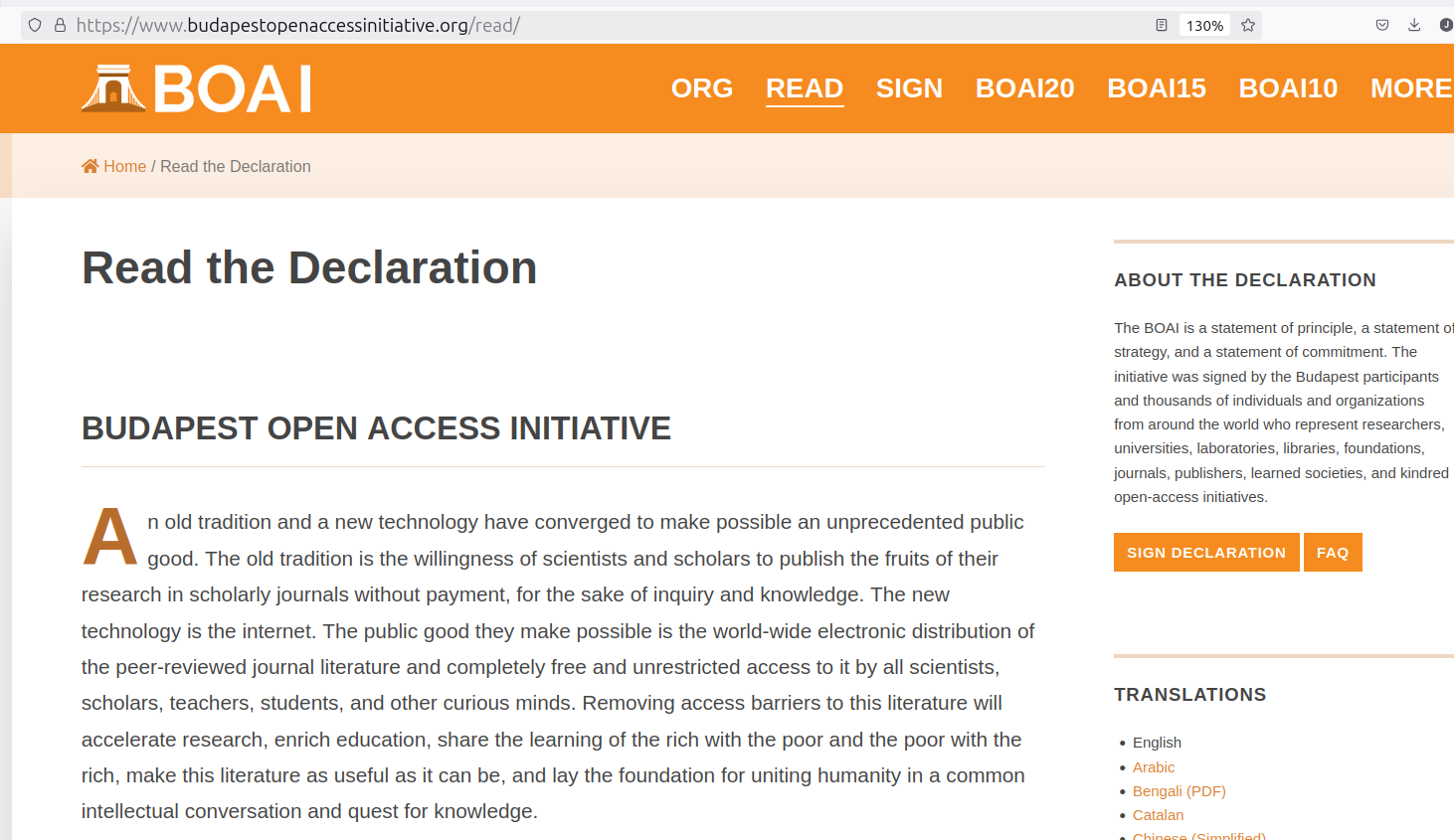 - https://www.budapestopenaccessinitiative.org/
- https://www.budapestopenaccessinitiative.org/
February 14, 2002
Budapest, Hungary
- removing access barriers to literature
- free and unrestricted online availability = open access
- experiments show that the overall costs of providing open access to this literature are far lower than the costs of traditional forms of dissemination
- opportunity to save money and expand the scope of dissemination
- recommendations: self-archiving (I.) and a new generation of open-access journals (II.)
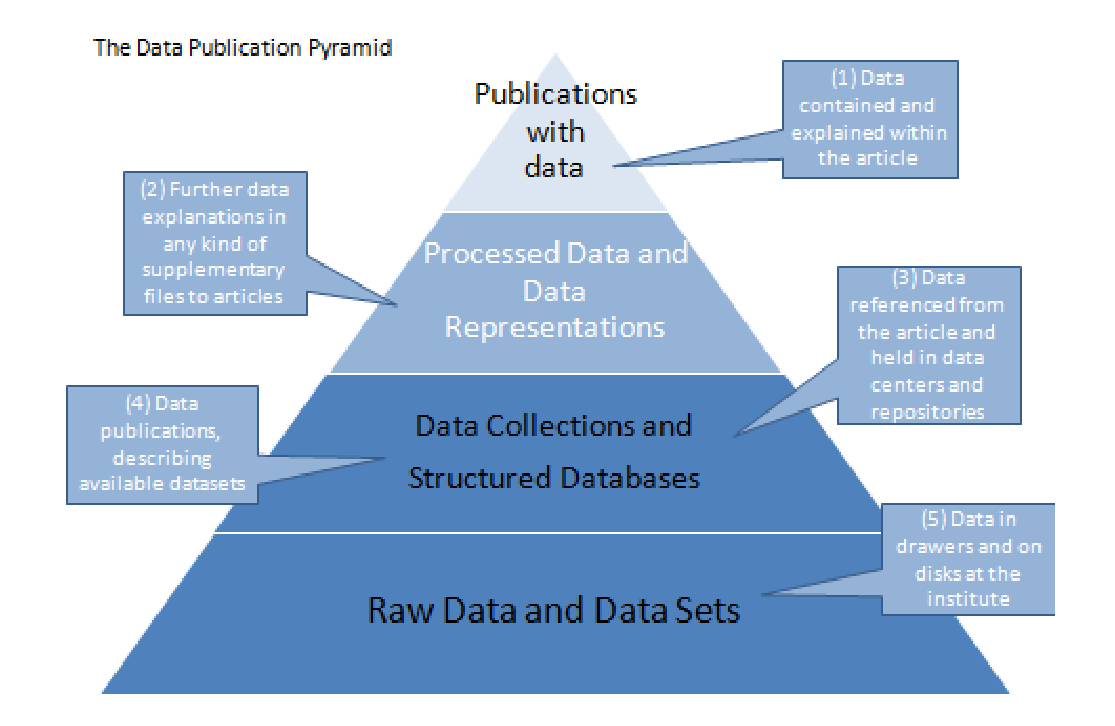
The FAIR Guiding Principles for scientific data management and stewardship

- emphasis on ability to programmatically find and use the data
- supporting its reuse
- accurare description
- https://www.go-fair.org/fair-principles/
One example - the Uniprot database
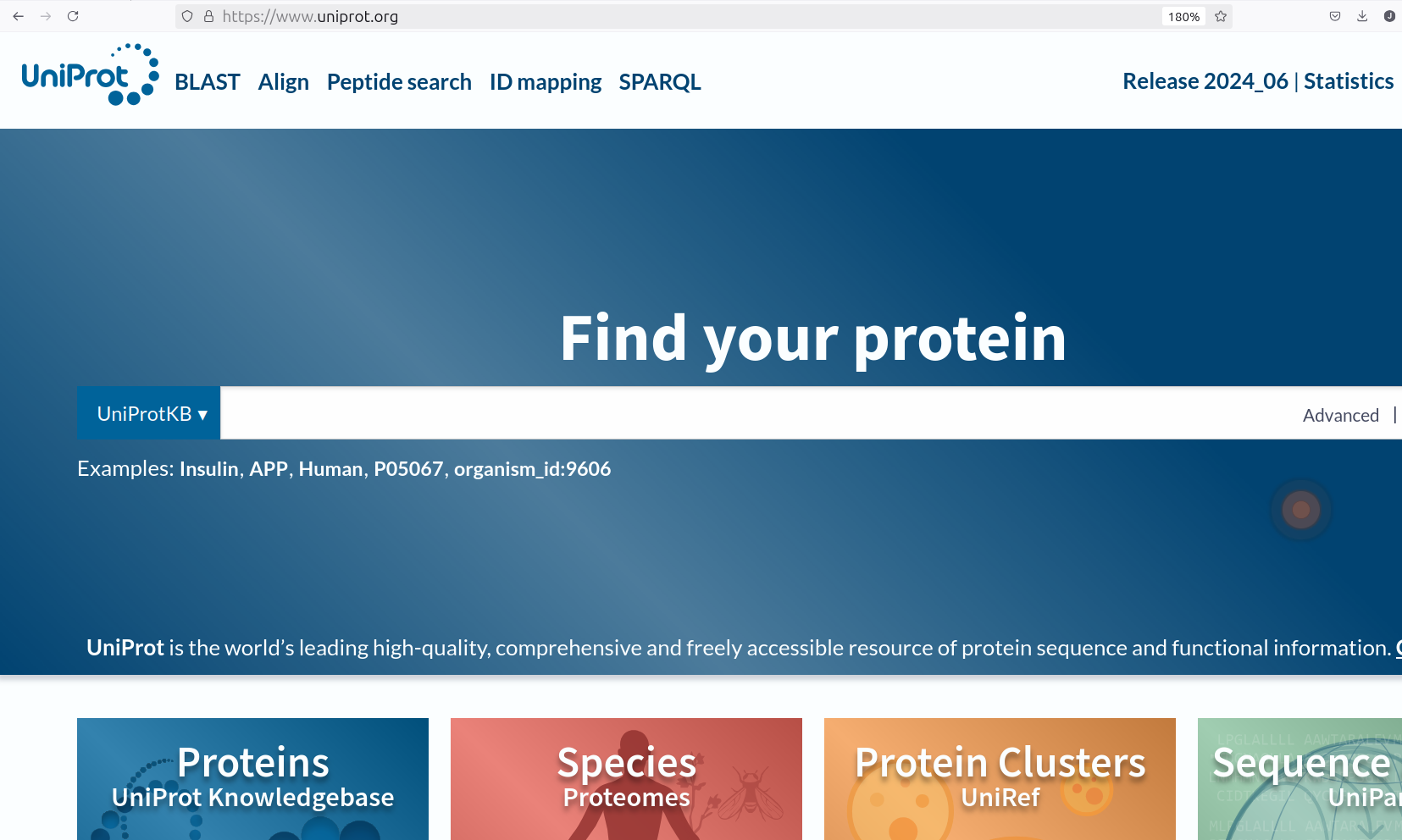
- a comprehensive resource for protein sequence and annotation data
- entries uniquely identified by a stable URL
- rich metadata that is both human-readable and machine-readable
- shared vocabularies and ontologies
- interlinking with more than 150 different databases
Most source data collected by scientists are not available
Majority high-impact cancer studies fail to replicate
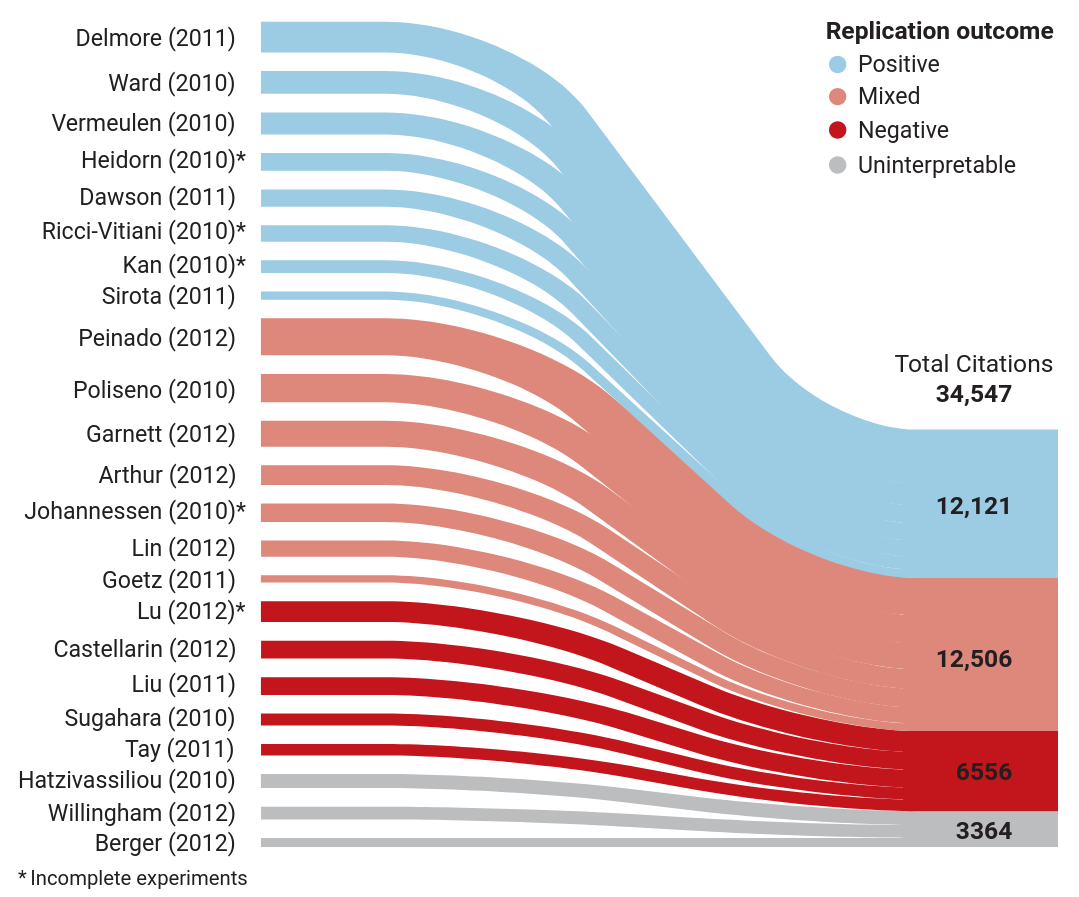
- The Reproducibility Project: Cancer Biology (RP:CB)
- failure to replicate 30 of 53 papers published by Science, Nature, and Cell from 2010 to 2012
- credibility of preclinical cancer biology?
- need for authors to share more details of their experiments
- vague protocols and uncooperative authors
- one-third of contacted authors declined or did not respond
Reporting and citation bias
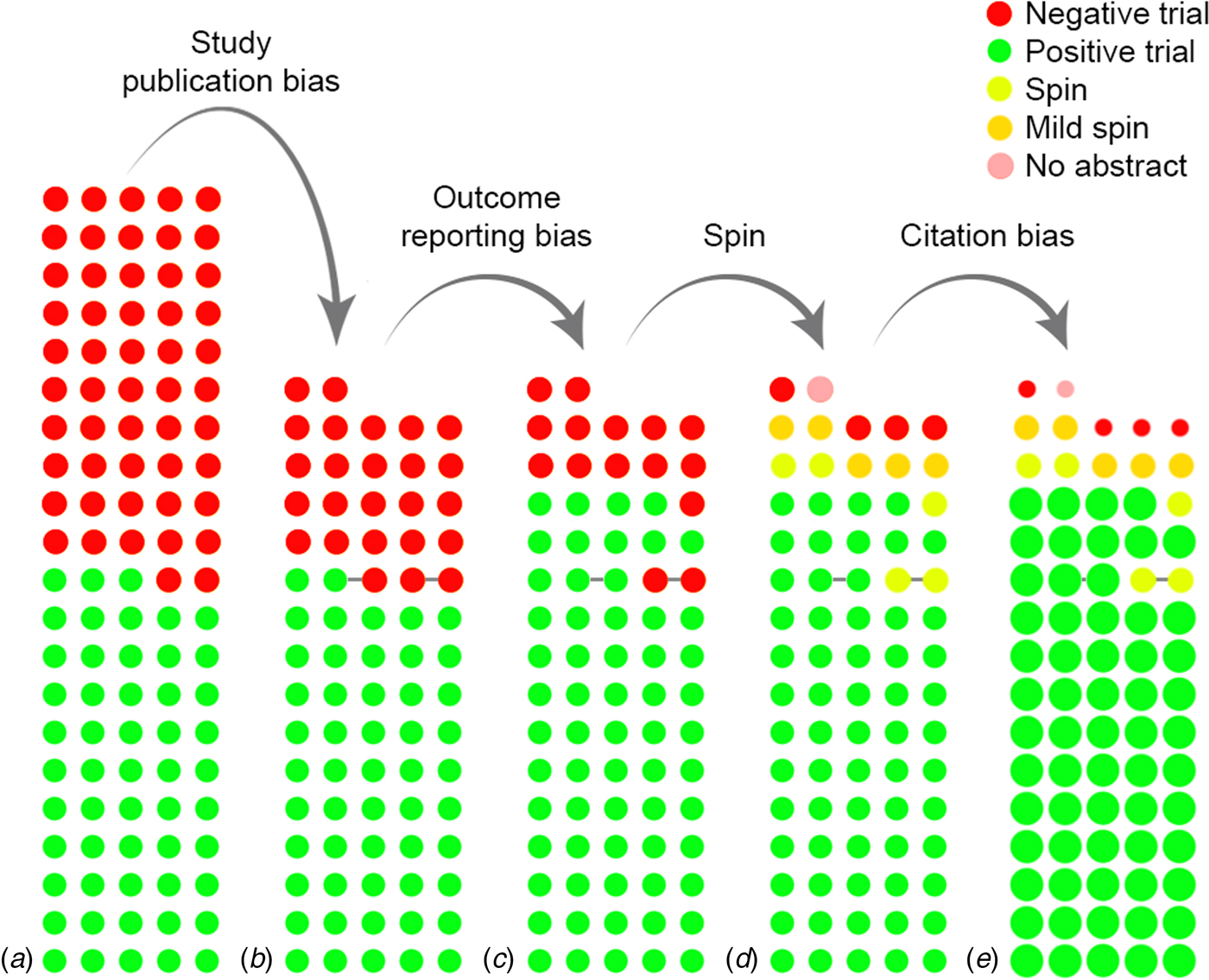
- The cumulative impact of reporting and citation biases on the evidence base for antidepressants
- up to half of all randomized controlled trials have never been published
- trials with statistically significant findings are more likely to be published than those without
- citation bias -> studies with positive results receive more citations than negative studies
Code is very often not shared or not shared stably

- study to assess the effectiveness of code sharing policy
- a random sample of 204 Science papers
- able to obtain artifacts from 44%
- able to reproduce the findings for 26%
- Typical responses:
“When you approach a PI for the source codes and raw data, you better explain who you are, whom you work for, why you need the data and what you are going to do with it.”
“I have to say that this is a very unusual request without any explanation! Please ask your supervisor to send me an email with a detailed, and I mean detailed, explanation.”
“The data files remains our property and are not deposited for free access. Please, let me know the purpose you want to get the file and we will see how we can help you.”
“We do not typically share our internal data or code with people outside our collaboration.”
Flipped protein structures due to buggy program
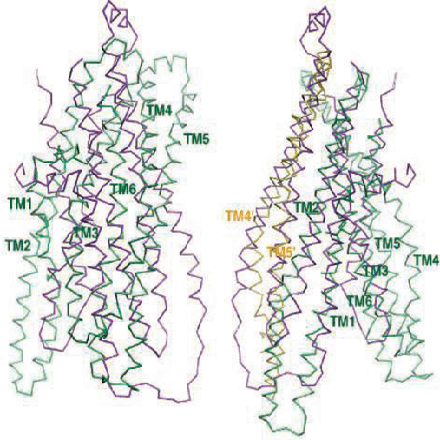
The structures of MsbA (purple) and Sav1866 (green) overlap little (left) until MsbA is inverted (right).
- buggy non-published program flipped two columns, inverting electron density
- program was inherited from another lab
- mistake repeated in several papers
- led to five retractions (three in Science)
Gene name errors are widespread in the scientific literature
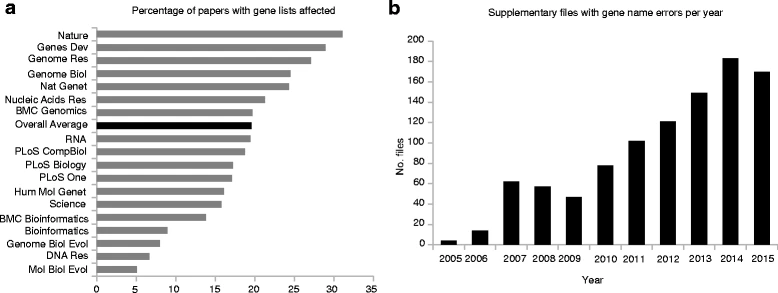
Most scientists use software developed for accounting

- the symbol MARCH1 has now become MARCHF1, while SEPT1 has become SEPTIN1, and so on
Current state of scholarly digital infrastructure and knowhow
An epidemic of retractions
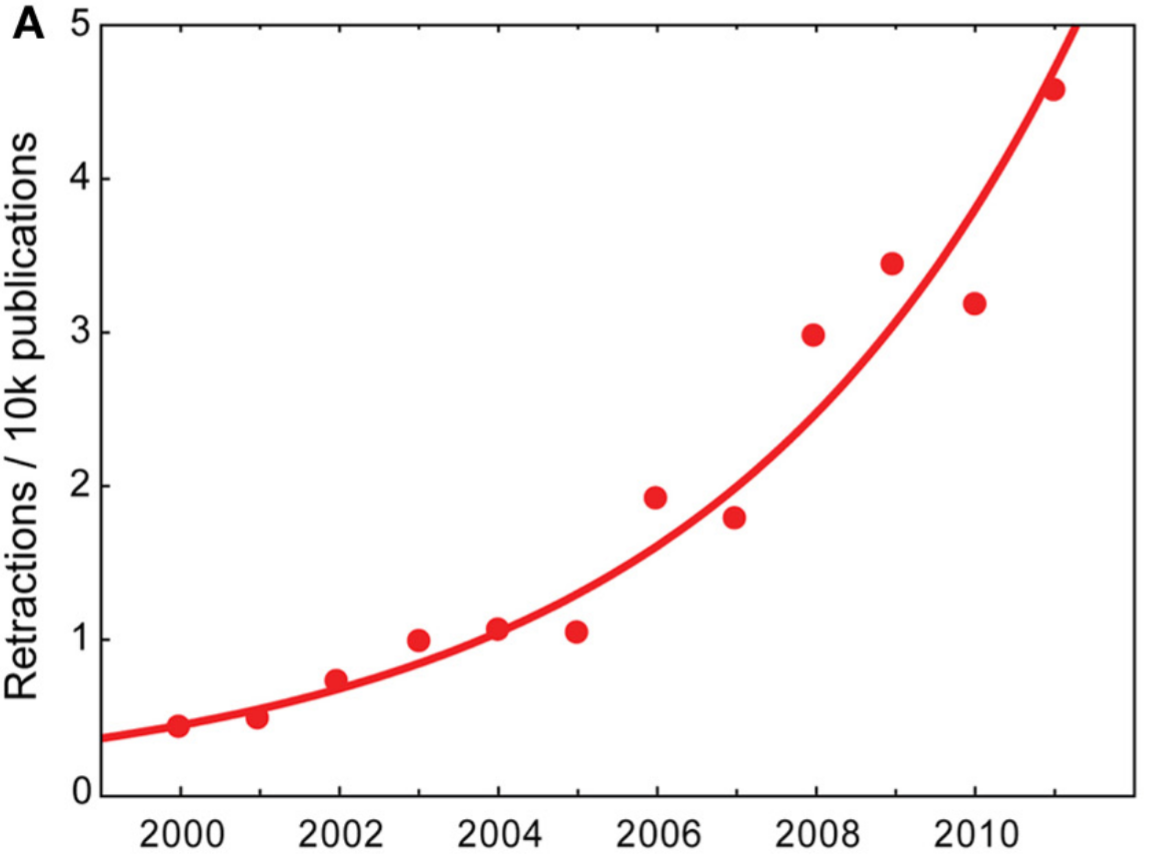
- exponential increase in retractions
- monitoring retractions: http://retractionwatch.com
- majority of all retractions is due to misconduct
Perverse incentives, publish or perish

- chasing titles, ‘stories’ and IF instead of scientific integrity, hypothesis-testing, rigour, openness
- under the spell of glamour journals
- “If I get this result, this will be a Nature paper!”
- reporting bias (only positive results are reported)
- low statistical power (a p-value of 0.05 brings only 50% reproducibility)
- in worst cases data are fabricated
IF - statistically flawed
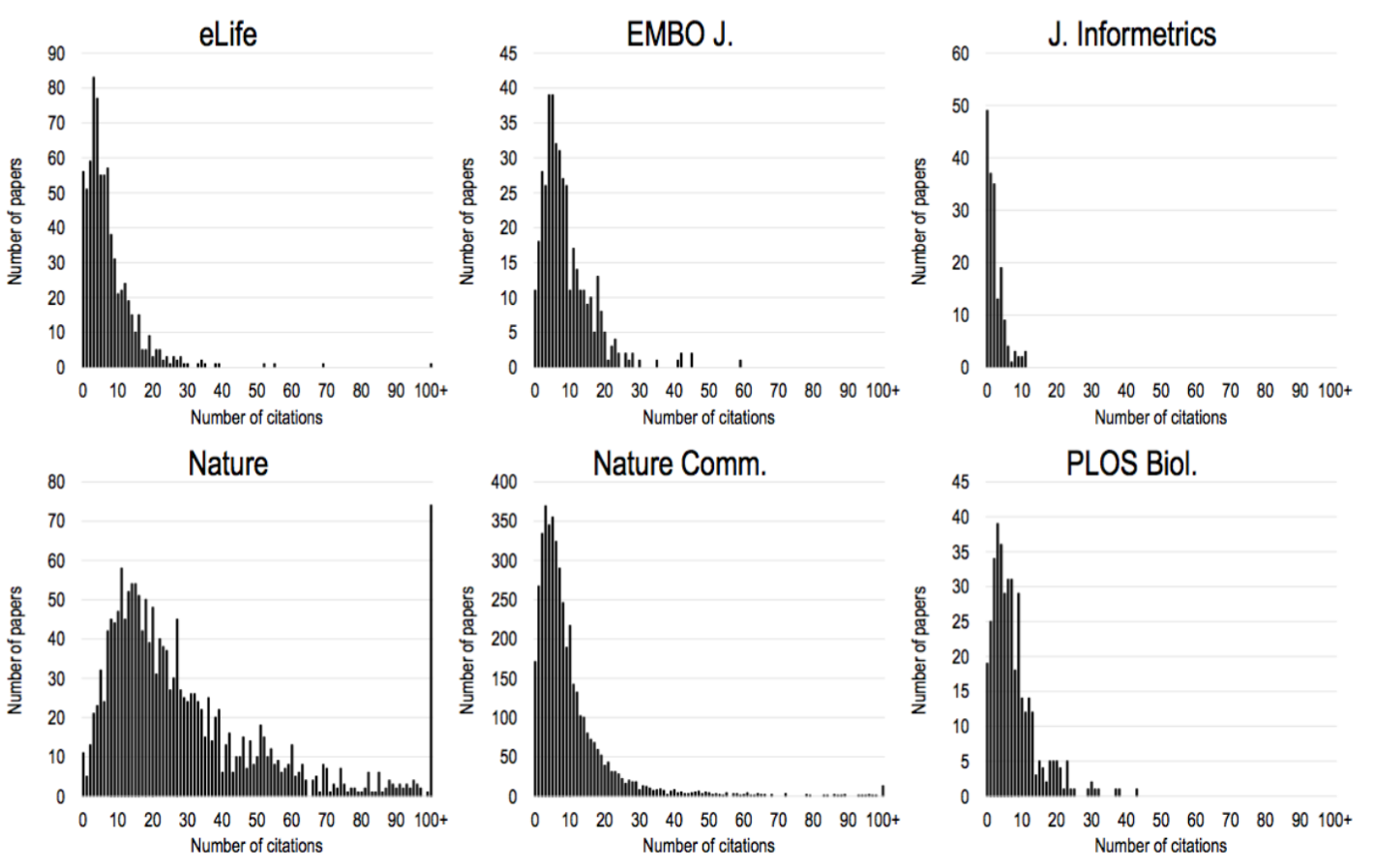
- highly skewed distributions
- journal IF comparisons: comparison of means of two populations
- allowed only if distributions follow a normal distributions!
- simple ranking by mean is incorrect
- median would be better or a more complex statistical test (e.g. Kruskal–Wallis test)
IF - strongly biased by outliers
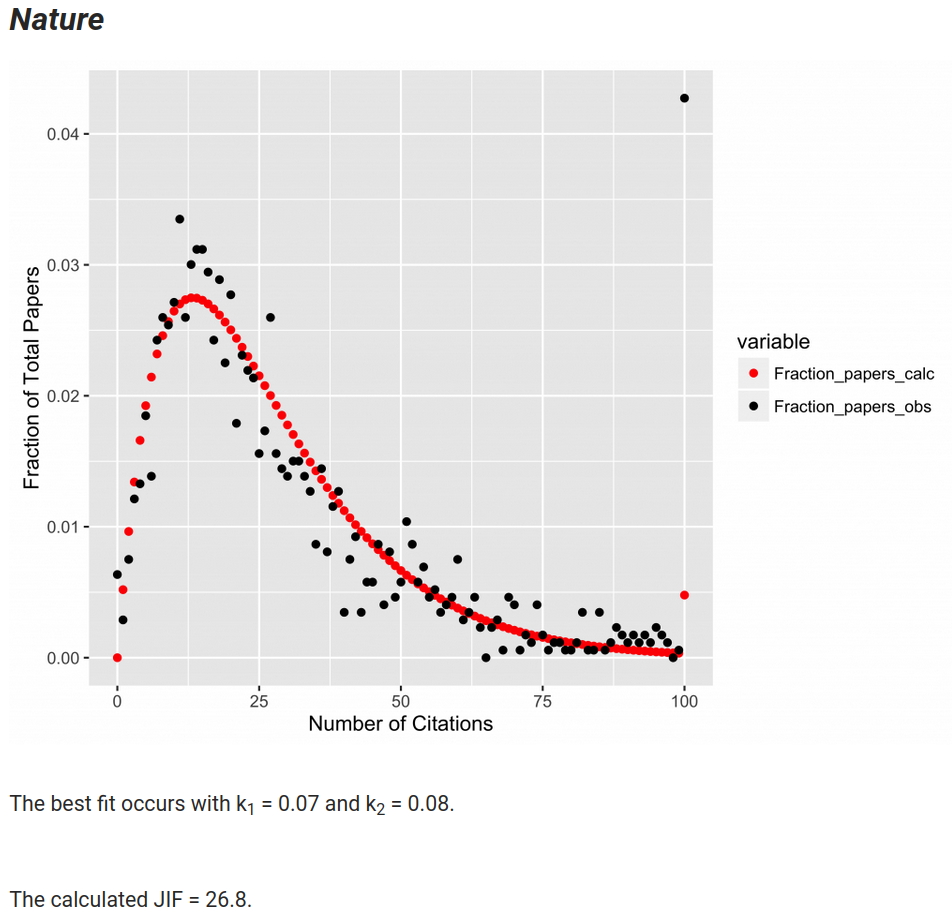
- fitting a more complex exponential function to the citation data
- a journal impact factor can be calculated from the parameters of the fit
- Science JIF = 25.3 instead of the reported 34
- Nature JIF = 26.8 instead of the reported 37
- a few highly cited papers have a substantial effect on the mean, but less on the exponential function
JIF does not correlate with quality metrics (e.g. statistical power)
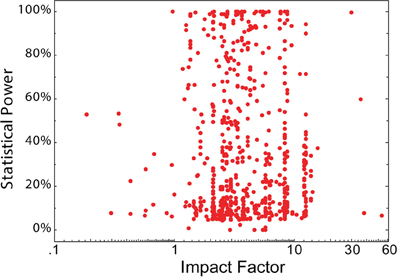
- no association between statistical power and journal IF
But: JIF correlates with retractions
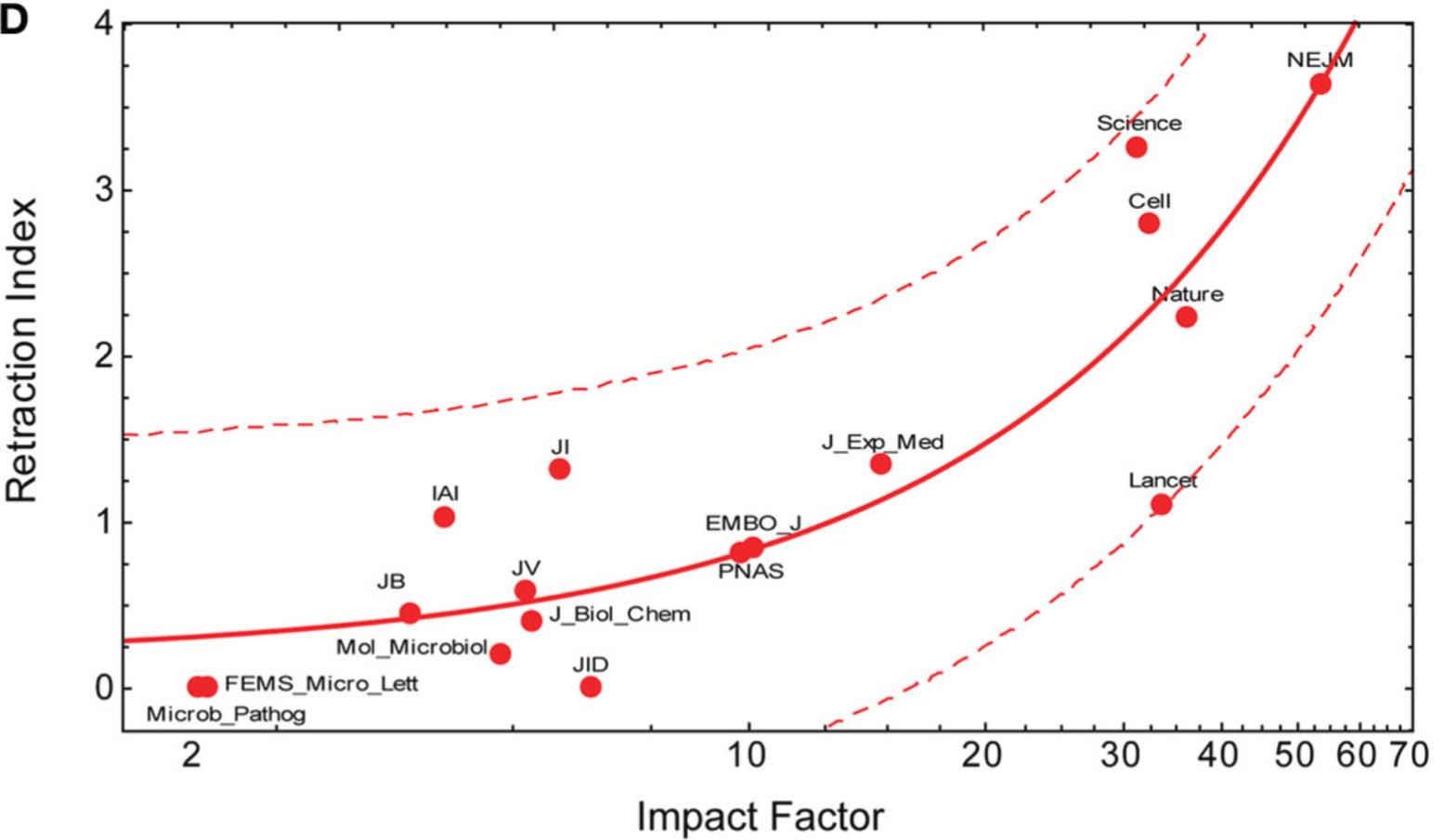
- journal rank is a strong predictor of the rate of retractions
- (also of Excel errors :))
Open Publishing and False Metrics
.jpg)
Harold Varnus
“We need to get away from false metrics and return to the task of looking at our colleagues’ work closely.”
- we continue to pay allegiance to the idea that the most important work is published in so-called ‘high-impact’ journals
- ceding judgments to journal editors, rather than retain it among working scientists
- we have to eliminate the current situation in which the fate of an individual researcher and their trainees depends on publishing in certain journals
- once we achieve that, we’ll eliminate a lot of distinctions between journals
- also eliminate resistance to open access
New approaches to research assessment
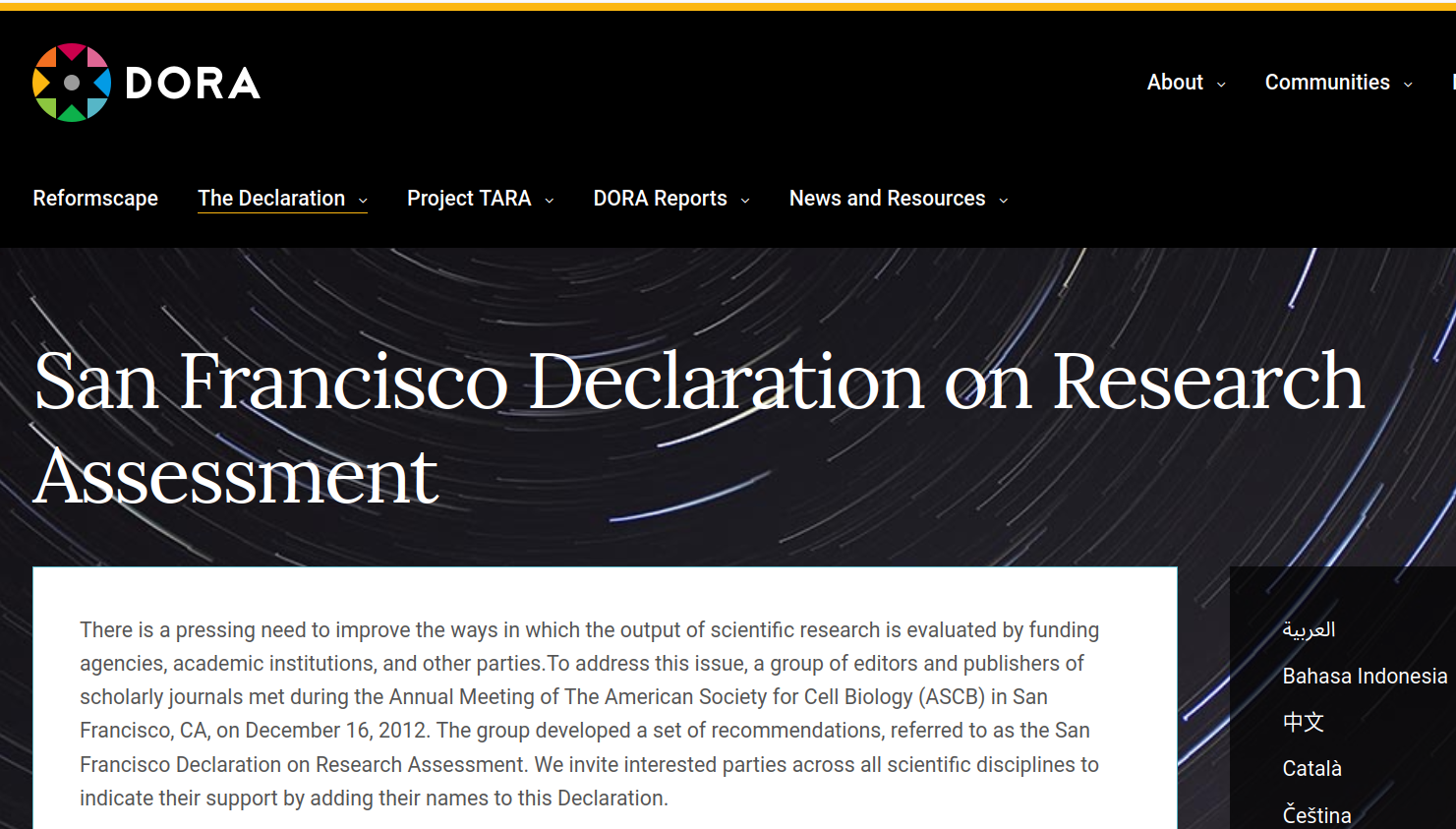
- the San Francisco Declaration on Research Assessment
- eliminate the use of journal-based metrics, such as Journal Impact Factors, in funding, appointment, and promotion considerations
- assess research on its own merits rather than on the basis of the journal in which the research is published
- capitalize on the opportunities provided by online publication (e.g. relax limits on the number of words, figures, and references)
Progress is slow and hijacked
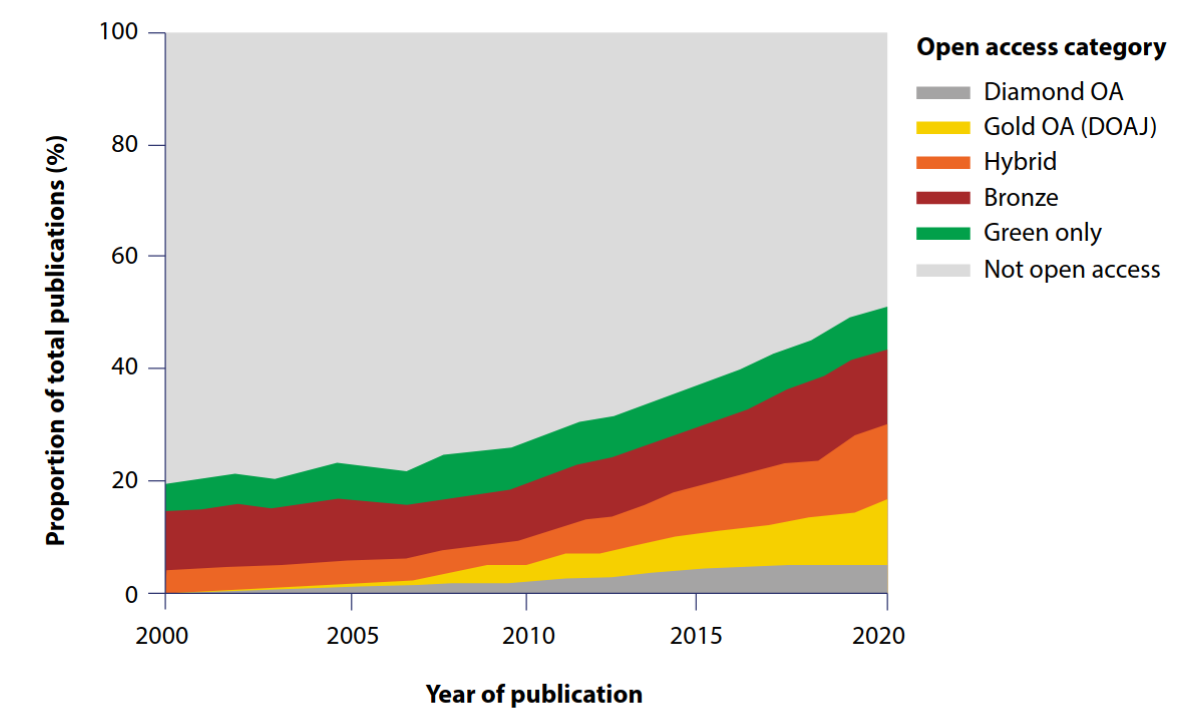
- Diamond: article published in an open access (only) journal without an article processing charge
- Green only: not openly accessible from the publisher website but a free copy is accessible via a repository or other platform
- Gold: article published in an open access (only) journal that includes article processing charges (profits can remain high!)
- Hybrid (profits can remain high!)
- Bronze: free to read on the publisher’s website, but with no identifiable licence
Current system is hugely wasteful
 Robert Maxwell in 1985. Photograph: Terry O’Neill/Hulton/Getty
Robert Maxwell in 1985. Photograph: Terry O’Neill/Hulton/Getty
- worldwide sales > USD 19 billion
- dominated by five large publishing houses: Elsevier, Black & Wiley, Taylor & Francis, Springer Nature and SAGE
- Elsevier has a profit margin around 40 % (higher than Microsoft, Google and Coca Cola)
- about USD 6 billion per year goes to profits = 2 CERNs/year
- APCs can be as high as $10,000
Kleptistan (Binjistan) - II



- workflow monopoly
- tools to cover the entire academic workflow
- e.g. Elsevier can now cover the entire workflow
- high risk of vendor lock-in
- preconditions for a functioning market exist, but a common standard is missing
Kleptistan (Binjistan) - III
or
How to milk the same cow multiple times?
- scientists provide content for free
- scientist peer review for free
- scientists buy over-priced product as APC, subscription or ‘transformative’ deals
- publisher (now ‘data analysis company’) sells entire workflows to scientists
- publishers tracks scientists on its platforms
- sells the data to the employers (e.g. quality assessment) or third parties
Unacceptable practices of data tracking by publishers
![]() Watchthem ‘Data gathering is an essential process, and most companies use it for their success.’
Watchthem ‘Data gathering is an essential process, and most companies use it for their success.’
- tracking site visits via authentication systems to detailed real-time data on the information behaviour of individuals and institution
- page visits, accesses, downloads, etc. – assembly of granular profiles of academic behaviour – without user consent
- selling the data, e.g. RELX – the parent company of Elsevier – establishes PURE at universities around the world
- to provide ‘insights’ into the entire research cycle
Open Science under attack

Dear Valued Professor,
Please be joining us for the next installment of our top quality scientific program at the 423rd International Conference on …
- overt commercial predation
- monetization of academic research output
- predatory journals and conferences
- the falsification of experimental evidence
- fake qualifications, certificates and awards
- predatory preprint servers
- surveillance by legacy publishers (e.g. Elsevier)
Open Science under attack
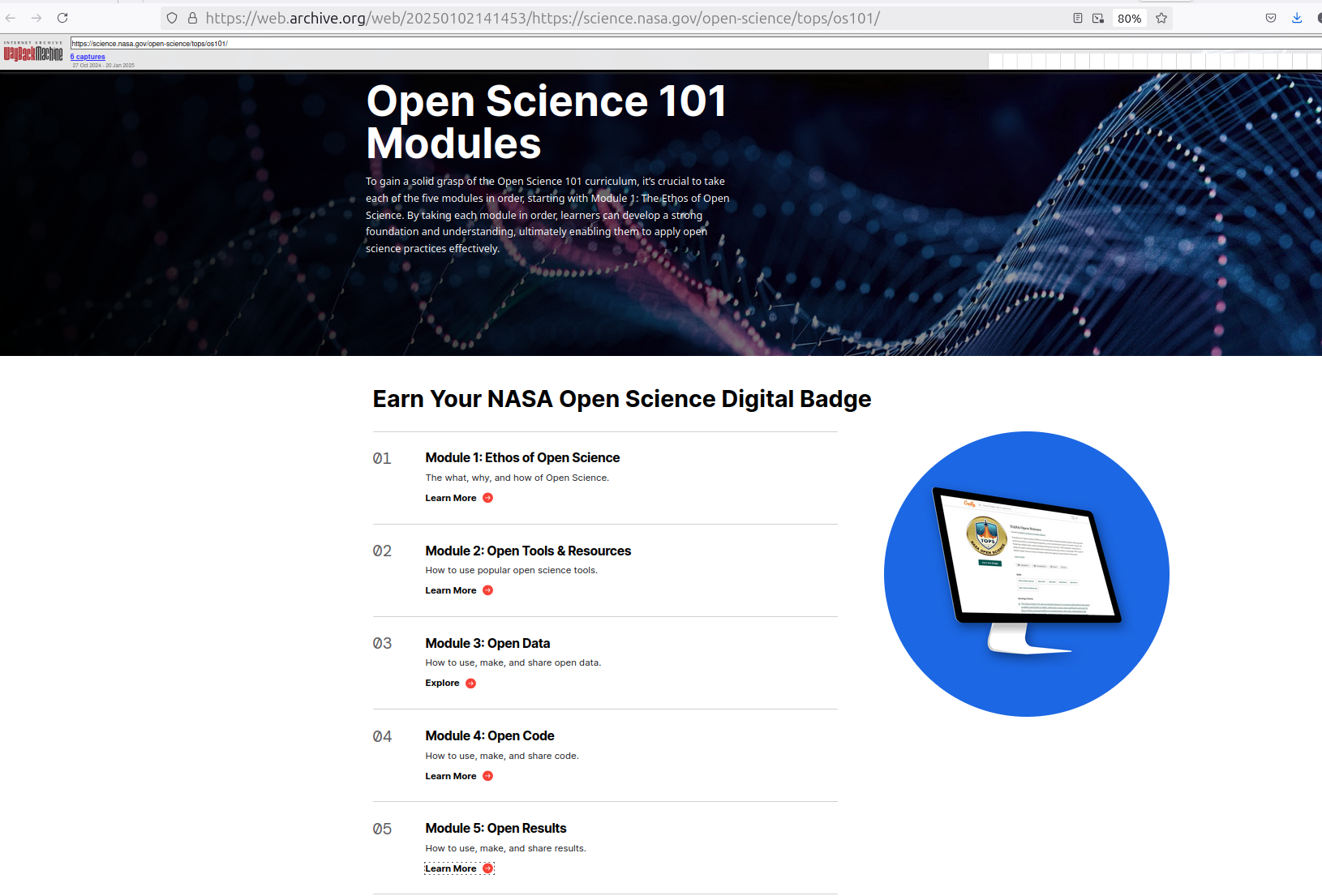
- As recently as January 2, 2025, NASA had five modules for teaching Open Science on its web site.
- The Trump administration has taken them down
Open Science under attack
- US left the WHO under Trump
- US was the largest funder
- does not bode well for fighting future pandemics
- open data was key to track new strains and spread
Major repositories and databases in constant danger


What should scientists and institutions do?
for the realist:
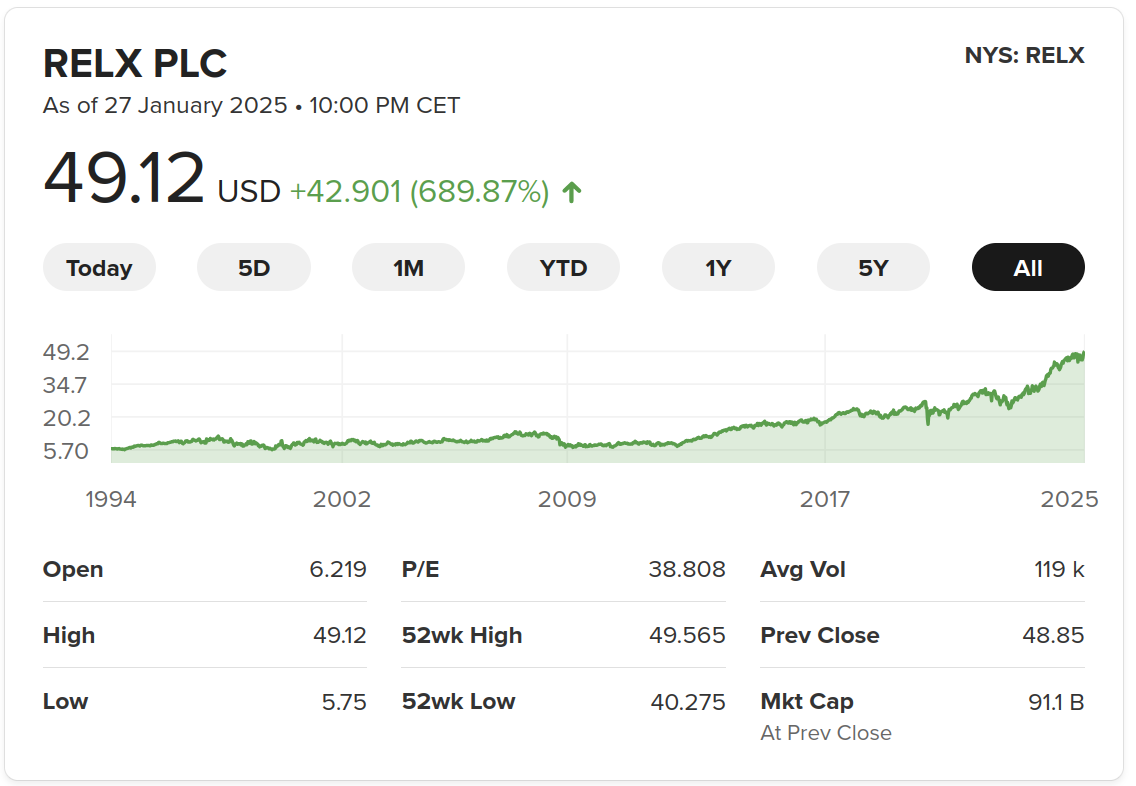
Safest bet: buy RELX stocks
(RELX: parent company of Elsevier)
What should scientists and institutions do?
for the idealist:
Taking back control

- Public institutions (universities, libraries, funders etc.) should take back control of the digital scholarly infrastructure
- create conditions of open competition for private sector (not oligopoly of a few publishers)
- control data, text, code, citation metrics, scholarly workflows, databases, standards etc.
- cancel all subscriptions and use money to fund databases, libraries, publishing etc.
- support initiatives like OpenAIRE
Open Alex
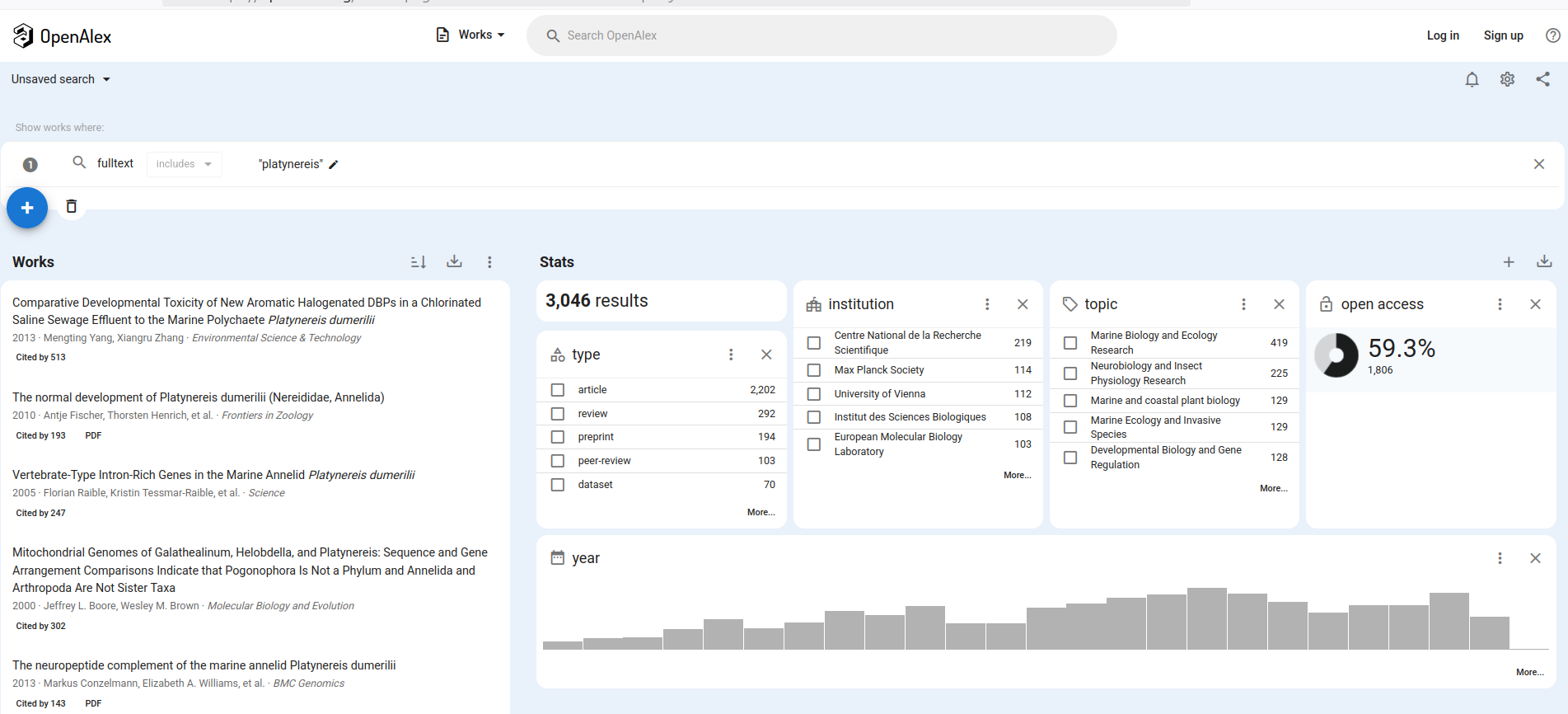
- https://openalex.org/
- indexes over 250M scholarly works
- nlamed after the ancient Library of Alexandria
- export all search results for free
- use of API or download the whole dataset
- share and reuse as you like
- made by OurResearch, a nonprofit dedicated to making research open
- 100% of source code is open
eLife
- funded by HHMI, Wellcome Trust, MPS, K&A Wallenberg Foundation
- https://elifesciences.org/
- The eLife process has five steps:
- Submission or transfer of a preprint from bioRxiv
- Peer review (eLife editors - who are all active researchers - discuss new submissions and decide which will be peer reviewed)
- Publication of Reviewed Preprint
- Publication of revised version
- Publication of Version of Record
- papers published together with eLife Assessment
EBI Bioimage Archive
https://www.ebi.ac.uk/bioimage-archive/
free, public resource for biological images
funded by UKRI and EMBL member state funding
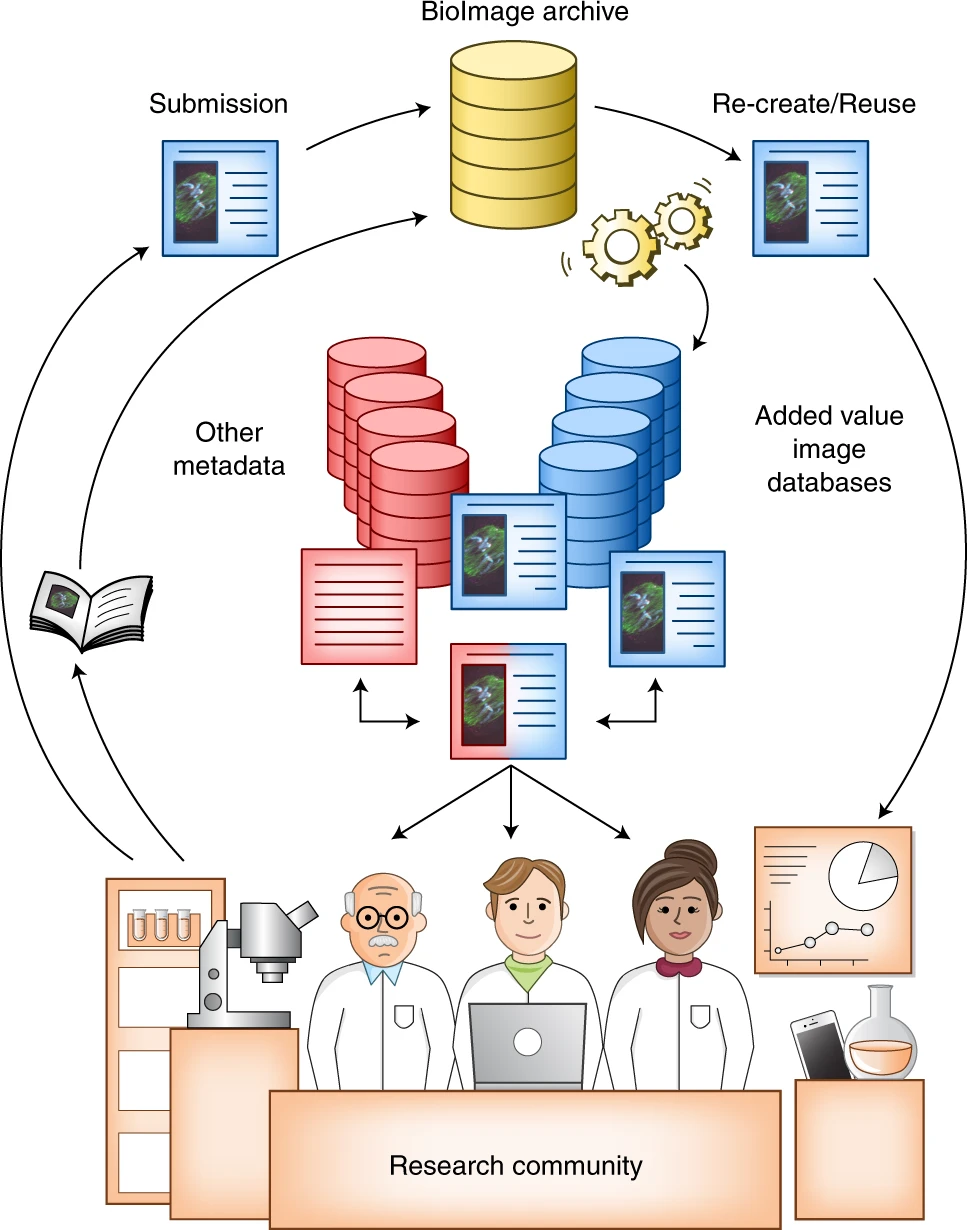
What is the solution? - The Fediverse for Science
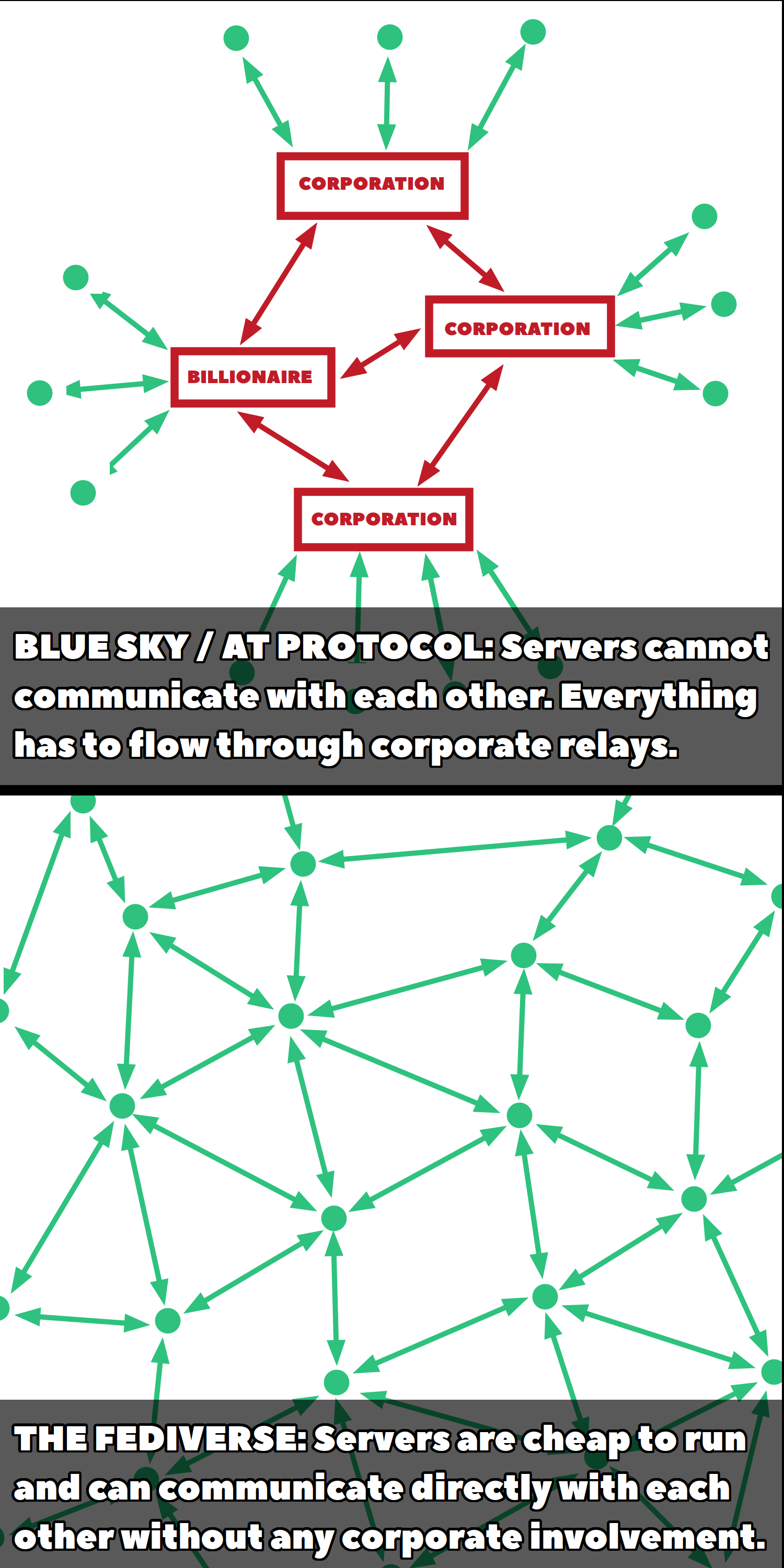
- a federated infrastructure
- run by public institutions (universities, libraries etc.)
- for communication (microblogging = Mastodon)
- for code (GitLab), data (e.g. Omero), text (preprint servers) etc.
- taking back control of scholarly infrastructure
Towards a new, federated scholarly infrastructure
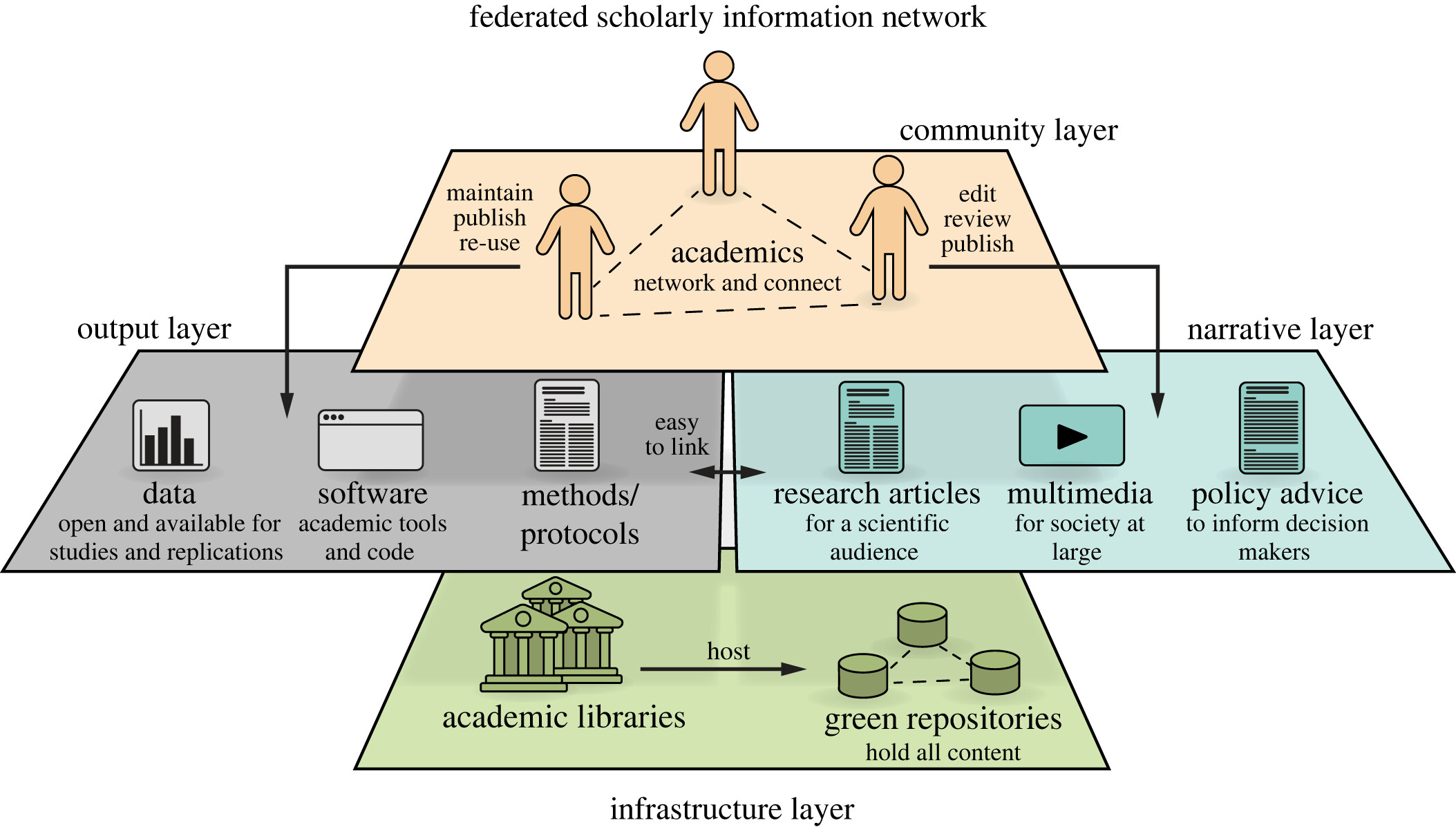
- plan for a federated scholarly information network
- a system that cannot be taken over by corporations
- designed redundantly
- open standards
- “a decentralized, resilient, evolvable network that is interconnected by open standards and open-source norms under the governance of the scholarly community”
One example for publishing - Open Research Europe (ORE)
- open access publishing venue for EC-funded researchers
- no author or reader fees
- Diamond (but authors need to be EC funded)
- maintained by the European Commission
- Wellcome Open Research (https://wellcomeopenresearch.org/) is similar, maintained by the Wellcome Trust
- open up access methods, results, publications, data, software, materials, tools and peer reviews
- standard tender process held regularly
- no lock-in with a single publisher
- regular procurement processes, no monopoly, fair prices
Sharing code in an ideal world - federated GitLab servers
- Institutions should host their GitLab server for code
- (GitLab is a database-backed web application running git)
- (git is a Distributed Version Control Systems)
- servers should be federated
- European (-> world-wide) network of research/education institutions and libraries
- code shared upon publication in a permanent repo with DOI
Code with persistend DOI
- Permanent repository for data, text and code
- integration with GitHub
- version control
- Safe — your research is stored safely for the future in CERN’s Data Centre for as long as CERN exists
- citeable
- usage statistics
An European Infrastructure for Open Science
 https://open-science-cloud.ec.europa.eu/
https://open-science-cloud.ec.europa.eu/
- Available Services:
- File Sync & Share
- Interactive Notebooks
- Large File Transfer
- Virtual Machines
- Cloud Container Platform
- Bulk Data Transfer
…still early days
While we wait…
- individual labs can change behaviour
- my lab has completely switched to publishing preprints and in OA-only not-for-profit journals
- raise your voice in hiring/promotion committees for DORA principles
Summary

“Open Science in (In)Action: Why, What, and How”
Gáspár Jékely
Centre for Organismal Studies, Heidelberg University
- open science is key for reproducibility, scientific progress, integrity, global fairness, resilience, cost-cutting
- solutions exist and are scaleable
- money could come by scaling back payment to legacy publishers
- problems: inertia, lack of coordination, lack of understanding the landscape, political and corporate takeover, prestige and other incentives to maintain status quo
